《비유》 큐레이션
디지털 전환과 문학의 언어
문학 연구와 평론 활동을 함께 하는 요즘, 내 활동들이 어떤 경계에 놓여있다는 생각을 자주 한다. 특히 디지털인문학 연구를 할 때 이 지점이 선명해진다. 질적 연구와 양적 연구, 문학과 기술, 언어학과 문학, 환원 불가능한 텍스트 해석과 측정 기반 전산 분석 방법들.
디지털 매체와 문학의 관계에서 웹진 《비유》가 중요한 역할을 담당하고 있는 만큼 《비유》에서는 이에 관한 논의들을 찾아볼 수 있다. 차현준이 「《비유》 파편 커스터마이징」(70호, 2024년 11월 6일)에서 《비유》의 형식 구조를 논하고, 임고은이 「우리가 ‘우리’로 만나는 곳」(68호, 2024년 7월 17일)에서 《비유》의 개편 과정 중 특별한 기억으로 “1,100여 편의 글을 읽어나가다 보면 (…) 이삿짐을 꾸리는 사람처럼, 정확히는 그러다 발견한 편지 상자 앞에 주저앉아 반나절을 보내는 사람처럼 골몰”했던 순간들을 꼽는 것은 문학이 디지털 매체와 관계 맺은 웹진의 특성에서 비롯된다.
디지털 전환(Digital turn)의 시대, 문학이 웹으로 공개될 때 나타나는 중요한 변화 중 하나는 자연어와 0과 1의 구분에 기초한 기계어 사이를 오가는 변화, 일종의 번역 상태일 것이다. 우리가 타이핑하는 사이, 인간의 언어는 기계가 이해할 수 있도록 변환되고 그것은 다시 인간이 이해할 수 있는 자연어로 표현된다. 그리고 이 과정에서 언어의 양적 변환이 발생한다. 디지털인문학자 앤드류 파이퍼는 오늘날 시대적인 흐름 속에서 “문자와 숫자를 넘나드는 새로운 번역이 요구”되고 있다고 파악하며 “텍스트를 양으로 번역하는” 것이 이 시대의 압도적인 특징이라고 강조한 바 있다.1) 최근 LLM(Large Language Model)의 약진도 이 맥락 위에서 이해할 수 있겠다.
요즘 내 흥미를 끄는 것은 문학을 구성하는 언어의 양적 측면이다. 문학은 언어로 구성된 예술이다. 언어를 새롭게 바라볼 수 있는 관점이 부각되는 이 시점에 언어와 문학의 관계를 보다 탐구할 필요가 있다. 특히 언어의 양적 측면에 집중하면 인간의 ‘읽기’와는 다른 지점, 즉 기계가 문학 작품을 이해하고자 할 때 나타나는 새로운 가능성들을 기대할 수 있게 된다. 그런 의미에서 나의 주요 고민은 이것이다. 언어와 수의 경계를 넘나드는 문학 작품의 언어를 기계와 함께 이해한다면 무엇을, 어떻게 ‘읽을’ 수 있을까?
《비유》의 작품들은 어떤 언어적인 구성을 갖고 있을까. 큐레이션 원고를 고민하다 전산 분석의 관점에서 소소하게 《비유》의 작품들을 읽어보고 싶었기에 《비유》에 실린 작품들을 참고할 수 있는지 문의했다. 감사하게도 이 글에 한해 아카이브와 자료 활용을 허락받을 수 있었다. 약 1,100여 편의 동시, 동화, 청소년 소설, 청소년 시, 소설, 시, 리뷰, 비평, 산문, 희곡 자료를 활용할 수 있었는데, 이중 양적으로 적은 분야는 제외하고 동화, 소설, 동시, 시를 분석 대상으로 삼았다. 다만 텍스트 전처리를 완벽히 마치진 못했기에 아래 분석들은 전산으로 문학 작품을 읽는 한 방법으로 참고하는 정도로 이해하면 좋을 듯하다.
먼저 형태소 최다 빈도 측정으로 작품의 언어 구성을 분석할 수 있다. 형태소 분석은 인간이 일일이 파악하고 집계하기 까다로운 작은 단위를 빈도로 측정할 수 있게 한다. ‘Kiwi’2)로 각 장르의 형태소를 분석하고 일반명사 최다 빈도를 측정한 결과는 다음과 같다. 동화의 일반명사 중에는 ‘말’이 가장 높은 빈도로 나타났고, ‘엄마’ ‘때’ ‘아빠’ ‘사람’ ‘집’ ‘아이’ ‘소리’ ‘할머니’가 순서대로 이어졌다. 일반명사는 언어학에서 ‘Aboutness’, 즉 무엇에 관한 것인지 드러내는 내용어에 해당한다는 점에서 이 측정 결과들은 해당 텍스트가 어떤 단어들을 높은 빈도로 구성하고 있는지 그리고 무엇을 드러내는지를 가늠할 수 있게 한다. 소설의 경우, ‘말’ ‘사람’ ‘때’ ‘생각’ ‘일’ ‘집’ ‘엄마’ ‘손’ 순으로 높은 빈도를 보였다. 물론 보다 꼼꼼히 따져볼 필요가 있겠지만, 두 장르의 어휘 빈도를 직관적으로 파악하면 동화에는 ‘엄마’가 2순위, ‘아빠’가 4순위의 빈도로 확인되는데 소설에서는 ‘엄마’가 7순위인 반면 ‘아빠’는 61순위다. 이는 장르별 ‘엄마’와 ‘아빠’의 빈도 차이를 측정할 수 있게 하는 한편 장르 내적으로 ‘엄마’와 ‘아빠’의 비중 차이를 구체적으로 파악할 수 있게 한다.
동시에서는 ‘엄마’ ‘집’ ‘눈’ ‘때’ ‘말’ ‘밤’ ‘나무’ ‘날’ ‘손’ ‘꽃’의 순으로, 시에서는 ‘사람’ ‘말’ ‘때’ ‘눈’ ‘속’ ‘생각’ ‘일’ ‘소리’ ‘손’ ‘위’ 순으로 최다 빈도 일반명사를 측정할 수 있었다. 추가로, 동시에서는 ‘꽃’ ‘바람’과 같은 단어들의 사용 빈도가 각각 10순위와 13순위인 반면 시에서는 59, 76순위에 머무른다. 이와 달리 ‘사랑’은 동시 상위빈도 100순위에 포함되지 못하는 반면 시에서는 18순위를 차지한다. 동화, 소설, 시 모두에서 중요하게 활용되는 ‘사람’은 동시의 상위 빈도 100순위에 포함되지 못한다는 점도 흥미롭다.
그런데 이러한 일반명사들도 전체 형태소의 양에 비하면 일부에 해당할 뿐이다. 예를 들면 소설의 최다빈도 일반명사인 ‘말’은 129,220개로 형태소 상위 빈도 26순위에 그친다. 최다 빈도 형태소는 ‘.’, 총 1,514,888개에 달하는 마침표다. 소설에 마침표가 많다는 건 일견 특별하지 않지만, 마침표가 문장을 분할하는 기능뿐 아니라 빈도와 배치에 따라 특정한 리듬감과 연관된다는 점에서 보면 그 의미가 적지 않다는 점을 고려할 필요가 있다.
이외에도 엑셀에 출력된 문학 작품 형태소 리스트를 살펴보면 새삼 내가 저렇게 많은 단어를 만나왔는지를 곰곰이 생각하게 된다. 특별하다고 여겨지는 문장을 만날 때 밑줄 긋고 외우곤 했던 나의 기존 ‘읽기’에서는 파악할 수 없었던 수많은 단어가 엑셀에 나열되어 있기 때문이다. 그제야 읽는 과정에서 흐려지는 텍스트의 언어들, 무의식적으로 흘려 읽었지만 텍스트를 구성하고 다른 단어들과 얽히면서 문맥을, 의미를 구축했을 단어들이 눈에 들어온다. 최다빈도 측정은 기초적인 한 분석 방법일 뿐이지만, 이 분석에서도 인간이 쉽게 인지하지 못한 채 읽고 쓰는 언어의 빈도와 배치가 드러난다.
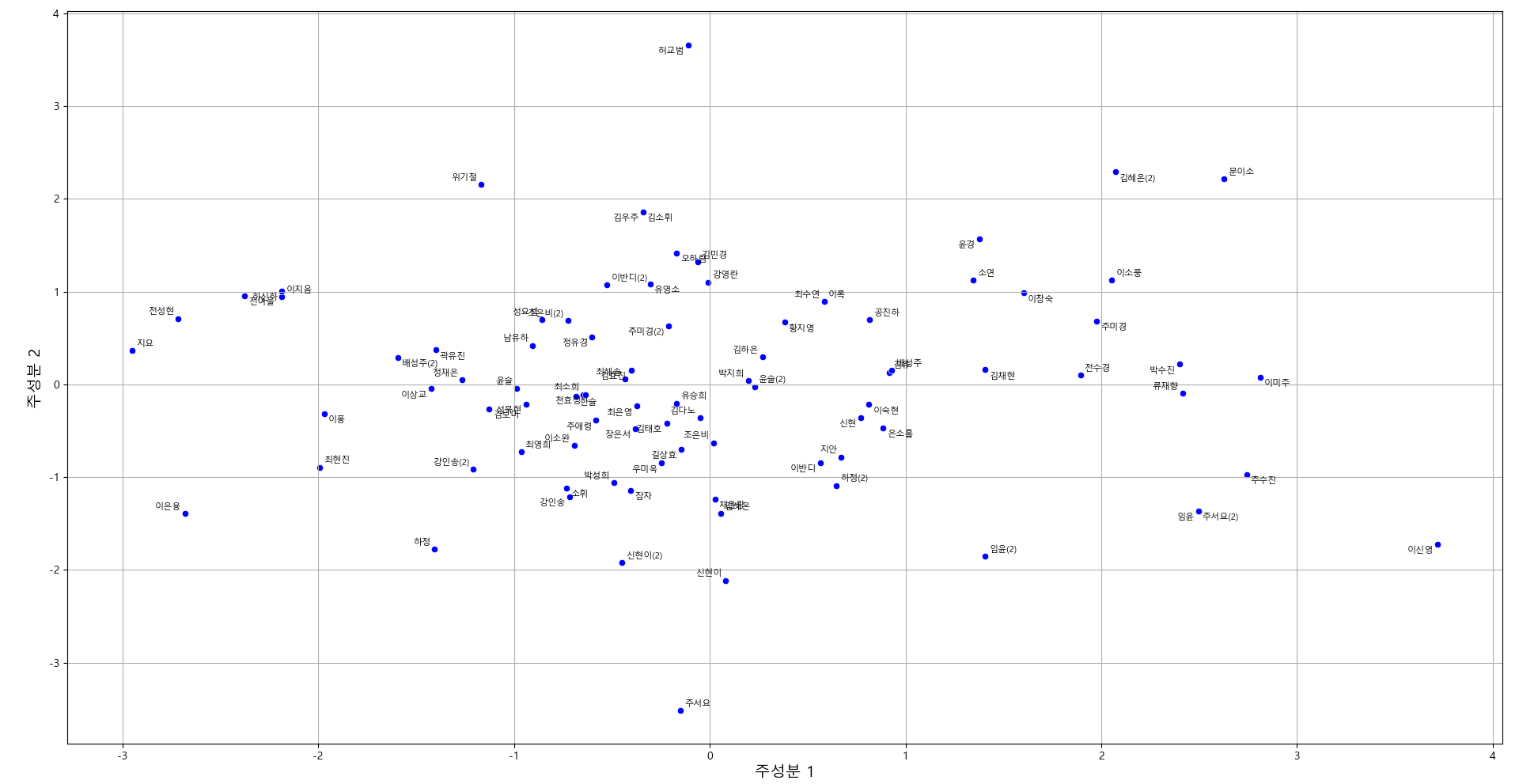
분량의 한계로 언어의 양을 활용한 분석을 더 수행하기는 어렵지만, 아쉬우니 내가 편애하는 동화(단편)로 한 가지 분석만 더 해보려 한다. 아래는 동화 작품들의 문체적 특성을 여섯 항목3)으로 분석한 측정값을 주성분 분석(PCA)으로 시각화한 것이다. X축이 주성분 1, Y축이 주성분 2로 구성되어 있으며, 주성분 분석은 인간이 통합적으로 이해하기 어려운 복합 정보를 이해할 수 있도록 종합하여 평면에 배치한다. 작품 제목이 긴 까닭에 작가의 이름으로 대체하고 작가 이름이 중복일 경우 (2)와 같이 표기했다. 자세히 설명하기에는 분량에 한계가 있지만 요약하면 해당 작품의 문체 측정치의 유사도가 높으면 가까이, 유사도가 낮으면 멀리 배치된다. (0,-2) 부근 신현이 작가, (-1,-1) 부근의 강인송 작가, (2,-2) 부근 임윤 작가의 두 작품의 문체가 유사하게 측정되고 있다는 점이 눈에 띄기도 한다.4)
문학은 간단한 분석만으로 파악하기에는 복잡하고 촘촘하게 구성된 텍스트인 까닭에, 아직 이러한 작품 이해 방법이 깊게 논의되지는 못하고 있다. 그럼에도 시대적인 흐름은 기술과 문학의 접목에 열려 있다. 다만 인간이 기술을 사용한다는 관점으로는 충분하지 않다. 이는 오히려 접촉이며, 접촉은 서로 간 만남을 전제한다. 김뉘연의 두 작품 「뉴 패치」와 「기록」(61호, 2022년 12월 27일)에는 인간이 기술을 활용하는 과정들이 표현된다. 특히 「기록」에서는 인간이 프로그램과 접촉해 “프로그램의 핵심 기능과 사용 방법을 이해”하는 대목이 있다. 이 접촉 의 ‘기록’은 또한 프로그램이 인간을 변화시키는 과정을 담고 있기도 하다.
경계에 서 있다는 것은 빈번하게 접촉하고 변화하고 있다는 의미인지도 모른다. 물론, 앞으로 무엇이 어떻게 변화할지 예측하기는 어렵기만 하다. 그럼에도 디지털 기술과의 접촉이 주는 어떤 불안과 기대 사이에서, 웹진 《비유》처럼 그 변화들을 꾸준히 탐색하고 나아가는 이들을 응원하고 싶다.
디지털 매체와 문학의 관계에서 웹진 《비유》가 중요한 역할을 담당하고 있는 만큼 《비유》에서는 이에 관한 논의들을 찾아볼 수 있다. 차현준이 「《비유》 파편 커스터마이징」(70호, 2024년 11월 6일)에서 《비유》의 형식 구조를 논하고, 임고은이 「우리가 ‘우리’로 만나는 곳」(68호, 2024년 7월 17일)에서 《비유》의 개편 과정 중 특별한 기억으로 “1,100여 편의 글을 읽어나가다 보면 (…) 이삿짐을 꾸리는 사람처럼, 정확히는 그러다 발견한 편지 상자 앞에 주저앉아 반나절을 보내는 사람처럼 골몰”했던 순간들을 꼽는 것은 문학이 디지털 매체와 관계 맺은 웹진의 특성에서 비롯된다.
디지털 전환(Digital turn)의 시대, 문학이 웹으로 공개될 때 나타나는 중요한 변화 중 하나는 자연어와 0과 1의 구분에 기초한 기계어 사이를 오가는 변화, 일종의 번역 상태일 것이다. 우리가 타이핑하는 사이, 인간의 언어는 기계가 이해할 수 있도록 변환되고 그것은 다시 인간이 이해할 수 있는 자연어로 표현된다. 그리고 이 과정에서 언어의 양적 변환이 발생한다. 디지털인문학자 앤드류 파이퍼는 오늘날 시대적인 흐름 속에서 “문자와 숫자를 넘나드는 새로운 번역이 요구”되고 있다고 파악하며 “텍스트를 양으로 번역하는” 것이 이 시대의 압도적인 특징이라고 강조한 바 있다.1) 최근 LLM(Large Language Model)의 약진도 이 맥락 위에서 이해할 수 있겠다.
요즘 내 흥미를 끄는 것은 문학을 구성하는 언어의 양적 측면이다. 문학은 언어로 구성된 예술이다. 언어를 새롭게 바라볼 수 있는 관점이 부각되는 이 시점에 언어와 문학의 관계를 보다 탐구할 필요가 있다. 특히 언어의 양적 측면에 집중하면 인간의 ‘읽기’와는 다른 지점, 즉 기계가 문학 작품을 이해하고자 할 때 나타나는 새로운 가능성들을 기대할 수 있게 된다. 그런 의미에서 나의 주요 고민은 이것이다. 언어와 수의 경계를 넘나드는 문학 작품의 언어를 기계와 함께 이해한다면 무엇을, 어떻게 ‘읽을’ 수 있을까?
《비유》의 작품들은 어떤 언어적인 구성을 갖고 있을까. 큐레이션 원고를 고민하다 전산 분석의 관점에서 소소하게 《비유》의 작품들을 읽어보고 싶었기에 《비유》에 실린 작품들을 참고할 수 있는지 문의했다. 감사하게도 이 글에 한해 아카이브와 자료 활용을 허락받을 수 있었다. 약 1,100여 편의 동시, 동화, 청소년 소설, 청소년 시, 소설, 시, 리뷰, 비평, 산문, 희곡 자료를 활용할 수 있었는데, 이중 양적으로 적은 분야는 제외하고 동화, 소설, 동시, 시를 분석 대상으로 삼았다. 다만 텍스트 전처리를 완벽히 마치진 못했기에 아래 분석들은 전산으로 문학 작품을 읽는 한 방법으로 참고하는 정도로 이해하면 좋을 듯하다.
먼저 형태소 최다 빈도 측정으로 작품의 언어 구성을 분석할 수 있다. 형태소 분석은 인간이 일일이 파악하고 집계하기 까다로운 작은 단위를 빈도로 측정할 수 있게 한다. ‘Kiwi’2)로 각 장르의 형태소를 분석하고 일반명사 최다 빈도를 측정한 결과는 다음과 같다. 동화의 일반명사 중에는 ‘말’이 가장 높은 빈도로 나타났고, ‘엄마’ ‘때’ ‘아빠’ ‘사람’ ‘집’ ‘아이’ ‘소리’ ‘할머니’가 순서대로 이어졌다. 일반명사는 언어학에서 ‘Aboutness’, 즉 무엇에 관한 것인지 드러내는 내용어에 해당한다는 점에서 이 측정 결과들은 해당 텍스트가 어떤 단어들을 높은 빈도로 구성하고 있는지 그리고 무엇을 드러내는지를 가늠할 수 있게 한다. 소설의 경우, ‘말’ ‘사람’ ‘때’ ‘생각’ ‘일’ ‘집’ ‘엄마’ ‘손’ 순으로 높은 빈도를 보였다. 물론 보다 꼼꼼히 따져볼 필요가 있겠지만, 두 장르의 어휘 빈도를 직관적으로 파악하면 동화에는 ‘엄마’가 2순위, ‘아빠’가 4순위의 빈도로 확인되는데 소설에서는 ‘엄마’가 7순위인 반면 ‘아빠’는 61순위다. 이는 장르별 ‘엄마’와 ‘아빠’의 빈도 차이를 측정할 수 있게 하는 한편 장르 내적으로 ‘엄마’와 ‘아빠’의 비중 차이를 구체적으로 파악할 수 있게 한다.
동시에서는 ‘엄마’ ‘집’ ‘눈’ ‘때’ ‘말’ ‘밤’ ‘나무’ ‘날’ ‘손’ ‘꽃’의 순으로, 시에서는 ‘사람’ ‘말’ ‘때’ ‘눈’ ‘속’ ‘생각’ ‘일’ ‘소리’ ‘손’ ‘위’ 순으로 최다 빈도 일반명사를 측정할 수 있었다. 추가로, 동시에서는 ‘꽃’ ‘바람’과 같은 단어들의 사용 빈도가 각각 10순위와 13순위인 반면 시에서는 59, 76순위에 머무른다. 이와 달리 ‘사랑’은 동시 상위빈도 100순위에 포함되지 못하는 반면 시에서는 18순위를 차지한다. 동화, 소설, 시 모두에서 중요하게 활용되는 ‘사람’은 동시의 상위 빈도 100순위에 포함되지 못한다는 점도 흥미롭다.
그런데 이러한 일반명사들도 전체 형태소의 양에 비하면 일부에 해당할 뿐이다. 예를 들면 소설의 최다빈도 일반명사인 ‘말’은 129,220개로 형태소 상위 빈도 26순위에 그친다. 최다 빈도 형태소는 ‘.’, 총 1,514,888개에 달하는 마침표다. 소설에 마침표가 많다는 건 일견 특별하지 않지만, 마침표가 문장을 분할하는 기능뿐 아니라 빈도와 배치에 따라 특정한 리듬감과 연관된다는 점에서 보면 그 의미가 적지 않다는 점을 고려할 필요가 있다.
이외에도 엑셀에 출력된 문학 작품 형태소 리스트를 살펴보면 새삼 내가 저렇게 많은 단어를 만나왔는지를 곰곰이 생각하게 된다. 특별하다고 여겨지는 문장을 만날 때 밑줄 긋고 외우곤 했던 나의 기존 ‘읽기’에서는 파악할 수 없었던 수많은 단어가 엑셀에 나열되어 있기 때문이다. 그제야 읽는 과정에서 흐려지는 텍스트의 언어들, 무의식적으로 흘려 읽었지만 텍스트를 구성하고 다른 단어들과 얽히면서 문맥을, 의미를 구축했을 단어들이 눈에 들어온다. 최다빈도 측정은 기초적인 한 분석 방법일 뿐이지만, 이 분석에서도 인간이 쉽게 인지하지 못한 채 읽고 쓰는 언어의 빈도와 배치가 드러난다.
분량의 한계로 언어의 양을 활용한 분석을 더 수행하기는 어렵지만, 아쉬우니 내가 편애하는 동화(단편)로 한 가지 분석만 더 해보려 한다. 아래는 동화 작품들의 문체적 특성을 여섯 항목3)으로 분석한 측정값을 주성분 분석(PCA)으로 시각화한 것이다. X축이 주성분 1, Y축이 주성분 2로 구성되어 있으며, 주성분 분석은 인간이 통합적으로 이해하기 어려운 복합 정보를 이해할 수 있도록 종합하여 평면에 배치한다. 작품 제목이 긴 까닭에 작가의 이름으로 대체하고 작가 이름이 중복일 경우 (2)와 같이 표기했다. 자세히 설명하기에는 분량에 한계가 있지만 요약하면 해당 작품의 문체 측정치의 유사도가 높으면 가까이, 유사도가 낮으면 멀리 배치된다. (0,-2) 부근 신현이 작가, (-1,-1) 부근의 강인송 작가, (2,-2) 부근 임윤 작가의 두 작품의 문체가 유사하게 측정되고 있다는 점이 눈에 띄기도 한다.4)
웹진 《비유》에 게재된 동화들의 문체 특성을 측정한 주성분 분석(PCA)
문학은 간단한 분석만으로 파악하기에는 복잡하고 촘촘하게 구성된 텍스트인 까닭에, 아직 이러한 작품 이해 방법이 깊게 논의되지는 못하고 있다. 그럼에도 시대적인 흐름은 기술과 문학의 접목에 열려 있다. 다만 인간이 기술을 사용한다는 관점으로는 충분하지 않다. 이는 오히려 접촉이며, 접촉은 서로 간 만남을 전제한다. 김뉘연의 두 작품 「뉴 패치」와 「기록」(61호, 2022년 12월 27일)에는 인간이 기술을 활용하는 과정들이 표현된다. 특히 「기록」에서는 인간이 프로그램과 접촉해 “프로그램의 핵심 기능과 사용 방법을 이해”하는 대목이 있다. 이 접촉 의 ‘기록’은 또한 프로그램이 인간을 변화시키는 과정을 담고 있기도 하다.
경계에 서 있다는 것은 빈번하게 접촉하고 변화하고 있다는 의미인지도 모른다. 물론, 앞으로 무엇이 어떻게 변화할지 예측하기는 어렵기만 하다. 그럼에도 디지털 기술과의 접촉이 주는 어떤 불안과 기대 사이에서, 웹진 《비유》처럼 그 변화들을 꾸준히 탐색하고 나아가는 이들을 응원하고 싶다.
심지섭
인하대 한국어문학과 박사. 『창비어린이』 신인문학상 평론 부문 수상(2024). 아동청소년문학 연구와 평론을 함께 하고 있으며 ‘어린이청소년SF연구공동체플러스알파’에서 활동중이다.
2025/07/02
- 1
- “Today, there is a new translational imperative at work, one that aims to move between letters and numbers. Translating texts into quanti-ties has emerged as the overwhelming feature of our cultural moment.” Andrew Piper, Enumerations: Data and Literary Study, University of Chicago Press, 2018, pp. 4-5.
- 2
- ‘Kiwi’는 ‘Korean Intelligent Word Identifier’의 약자로, 한국어 형태소 분석기다. 관련 정보는 다음의 논문 참고. 이민철, 「Kiwi: 통계적 언어 모델과 Skip-Bigram을 이용한 한국어 형태소 분석기 구현」, 『디지털인문학』 제1권 1호, 한국디지털인문학협의회, 2024, 109-136쪽. 바로가기
- 3
- 여섯 항목 중 다섯 항목은 박진호의 연구 「인공지능 기술을 인문학에 활용한다면?」(『디지털 시대, 인문학의 미래를 말하다』, 서울대학교 인문대학 엮음, 사회평론 아카데미, 2024, 203쪽)에 근거한 것이다. 1. 연결어미 대 전성어미 비율 (paratactic 대 hypotactic 비율) 2. 동사 대 형용사 비율 (서사적 문체 대 묘사적 문체) 3. 보조용언 ‘있-’의 비율 (서사적 문체 대 묘사적 문체) 4. 문장 길이(어절 수) (만연체 대 간결체) 5. TTR(type-token ratio)의 변형 (어휘 다양성). 이번 웹진 《비유》의 동화 분석에는 여섯 번째 항목으로 ‘대화의 비율’을 추가해 총 여섯 가지 문체 측정 항목으로 분석을 진행했다.
- 4
- 전산 문체 분석은 아직 연구 초기 단계인 까닭에 훨씬 다양한 방법들이 논의될 필요가 있다. 또한, PCA가 분석 자료 내 상대적인 비교라는 점과 이 분석의 전처리가 완벽하지는 않다는 점을 확인할 필요도 있겠다.