센시키-ㅌ
1화 낯선 작업
우리가 방점을 찍는 순간
“이 영화 보셨어요?”
새로운 대화를 시작하기에 좋은, 마법 같은 말이다. 누군가와 같은 경험을 공유한다는 그 자체로 우리는 굉장한 친밀감을 느낀다. 하지만 같은 영화를 보았어도 기억에 남는 대사나 장면이 저마다 다르다는, 어쩌면 당연한 사실을 얼마 지나지 않아 깨닫게 된다.
우리는 같은 것을 들어도 다른 것을 듣고, 같은 곳을 보아도 다른 곳을 본다. 왜 어떤 경험을 함께 나누었던 사람들의 기억과 감성은 서로 같은 값을 가지지 않는 것일까.
프로젝트팀 ‘키-ㅌ’는 그것이 ‘시선’의 차이에서 비롯된다고 생각했다. 모든 개인은 자신의 의견과 감성을 담은 시선으로 일상을 바라보고 있다. 모든 문학작품이 서로 다른 이야기를 하고 있는 이유 역시 작가가 삶을 바라보는 시선이 다르기 때문이다. 문학이란 개인이 일상에 던진 수많은 시선들이 언어의 형태로 모인 것이다. 우리는 모두 자신만의 고유한 시선을 가지고 있으며, 그것은 우리가 끊임없이 서로의 생각을 묻게 만드는 원동력이다. 같은 경험을 하고 같은 공간에서 시간을 보내도 우리가 방점을 찍는 순간이 다르다는 것. ‘센시키-ㅌ’ 프로젝트는 그 다름에 집중함으로써 개인의 일상, 나아가 그 일상에서 비롯된 문학을 좀더 새롭게 바라보고자 한다.
인공지능과 가상현실 등에 대한 작품을 읽으면서 자연스레 사람과 기계의 소통에 주목해온 키-ㅌ 팀원들은 문자가 기계에게 인간의 언어를 가장 정확하게 전달해줄 수 있는 매개체라고 생각했다. 사람들의 시선과 방점을 읽는 색다른 방법으로, 컴퓨터 프로그래밍을 이용해 우리의 일상 언어에서 흥미로운 정보를 찾아내고 분석해본다면 어떨까. 이는 ‘센시키-ㅌ’가 던지는 질문이자 찾고자 하는 답, 그리고 다음과 같은 새로운 실험을 시작하게 된 까닭이다.
*
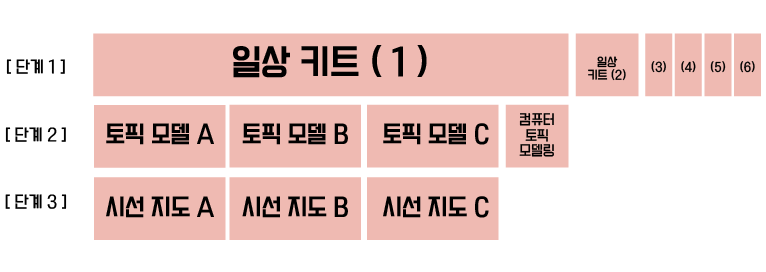
‘센시키-ㅌ’ 프로젝트의 작업은 크게 세 단계를 거친다. 첫번째 단계는 특정 테마에 대해 참여자들이 산발적으로 이야기를 나누는 단계이다(‘단계 1’). 다양한 이들의 시선과 이야기들이 모이고 흩어지는 모습 속에서, 일상에서 우리의 시선이 어디에, 어떻게, 왜 닿는지를 엿볼 수 있다. 대화의 대략적인 가이드라인을 위해 몇 가지 질문이 던져질 예정이다.
다음은 ‘단계 1’에서 나눈 대화를 스크립트로 작성하고 그를 바탕으로 토픽(주제어)을 추출한다(‘단계 2’). 선정된 토픽을 중심에 놓고 그와 관련된 단어들을 그룹으로 묶어 토픽 모델을 만든다.
예를 들어 『어린왕자』를 토픽 모델링 해보자. 위의 그림과 같이 토픽과 연결된 단어들이 추출된다. 컴퓨터는 『어린왕자』를 분석한 뒤 ‘어린왕자’라는 토픽이 소설에서 유의미한 주제어이며, ‘바오밥나무’ ‘오늘’ ‘장미’ 등의 단어가 토픽과 연관성 있게 사용되었다고 해석한다.
마지막으로는 ‘단계 2’에서 나온 모델을 토대로 ‘시선 지도’를 구현한다(‘단계 3’). 시선 지도는 토픽, 단어와 그를 잇는 선으로 구성된다. 토픽은 그룹으로 묶인 단어들의 중심에 위치하며 각 단어들은 토픽과 선으로 연결된다. 선 위에는 숫자가 적혀 있는데, 이 숫자는 토픽과 단어의 관계를 나타낸다. 선의 길이가 짧을수록, 즉 적힌 숫자가 작을수록, 토픽과 단어는 밀접한 관계를 가지고 있다.
『어린왕자』의 시선 지도를 살펴보자. ‘어린왕자’라는 토픽과 가장 밀접한 단어는 ‘나무’다. 텍스트에서 총 서른두 번 등장한 ‘나무’는 총 열아홉 번 등장한 ‘장미’보다 큰 글씨로 그려졌다. ‘마음’은 ‘사막’ 그룹과 ‘존재’ 그룹에 포함되어, 두 토픽에 동시에 연결되어 있다.
*
이렇게 만들어진 시선 지도를 모아 앞으로 컴퓨터와 팀원 개개인의 ‘시선 사전’을 만들고, 비교하고자 한다. 하나하나 쌓인 사람들의 ‘삶-문학’은 또다시 ‘시선-사전’이라는 낯선 형태로 표현될 것이다. 완성된 거대한 시선 사전을 펼치면 그 안에서 새로운 시선이 이어지지 않을까 기대하고 있다.
우리의 대화 안에는 일상의 매순간에서 비롯된 마음속 이야기들도 있겠고, 무의식중에 불현듯 떠오르는 생각들도 놓여 있을 것이다. 이는 서로에게 유의미한 정보일 수도, 가볍고 시시껄렁한 헛소리일 수도 있다. 하지만 자신만의 것이라고 생각했던 사적인 고민이나 생각들을 나누며 우리는 자신의 가장 개인적인 부분을 마주하고 가장 자신다운 것을 찾아보려 한다. 일상을 기술이라는 매개체를 통해 바라봄으로써 오히려 지금보다도 더 사적으로 이해할 수 있게 되길 바란다. 거기에서 아주 새로운 것, 우리만의 것이 태어날 수 있을 것이라고 믿는다.
새로운 대화를 시작하기에 좋은, 마법 같은 말이다. 누군가와 같은 경험을 공유한다는 그 자체로 우리는 굉장한 친밀감을 느낀다. 하지만 같은 영화를 보았어도 기억에 남는 대사나 장면이 저마다 다르다는, 어쩌면 당연한 사실을 얼마 지나지 않아 깨닫게 된다.
우리는 같은 것을 들어도 다른 것을 듣고, 같은 곳을 보아도 다른 곳을 본다. 왜 어떤 경험을 함께 나누었던 사람들의 기억과 감성은 서로 같은 값을 가지지 않는 것일까.
프로젝트팀 ‘키-ㅌ’는 그것이 ‘시선’의 차이에서 비롯된다고 생각했다. 모든 개인은 자신의 의견과 감성을 담은 시선으로 일상을 바라보고 있다. 모든 문학작품이 서로 다른 이야기를 하고 있는 이유 역시 작가가 삶을 바라보는 시선이 다르기 때문이다. 문학이란 개인이 일상에 던진 수많은 시선들이 언어의 형태로 모인 것이다. 우리는 모두 자신만의 고유한 시선을 가지고 있으며, 그것은 우리가 끊임없이 서로의 생각을 묻게 만드는 원동력이다. 같은 경험을 하고 같은 공간에서 시간을 보내도 우리가 방점을 찍는 순간이 다르다는 것. ‘센시키-ㅌ’ 프로젝트는 그 다름에 집중함으로써 개인의 일상, 나아가 그 일상에서 비롯된 문학을 좀더 새롭게 바라보고자 한다.
인공지능과 가상현실 등에 대한 작품을 읽으면서 자연스레 사람과 기계의 소통에 주목해온 키-ㅌ 팀원들은 문자가 기계에게 인간의 언어를 가장 정확하게 전달해줄 수 있는 매개체라고 생각했다. 사람들의 시선과 방점을 읽는 색다른 방법으로, 컴퓨터 프로그래밍을 이용해 우리의 일상 언어에서 흥미로운 정보를 찾아내고 분석해본다면 어떨까. 이는 ‘센시키-ㅌ’가 던지는 질문이자 찾고자 하는 답, 그리고 다음과 같은 새로운 실험을 시작하게 된 까닭이다.
‘센시키-ㅌ’ 프로젝트는 낯선 작업을 시작한다. 텍스트 마이닝을 기반으로 한 토픽 모델링이라는 기술을 이용한다. 쉽게 말하자면 컴퓨터 프로그래밍을 이용한 텍스트 연구로, 텍스트의 맥락과 의미에 따라 단어를 그룹으로 묶어 주제(토픽)를 추론해보는 것이다. 2주에 한 번 키-ㅌ 팀원과 외부 참여자들이 이 작업에 함께할 예정이며, 그 과정을 연재를 통해 기록하고 소개하고자 한다.
‘센시키-ㅌ’ 프로젝트 작업 과정을 단계별로 살펴본다면……
‘센시키-ㅌ’ 프로젝트의 작업은 크게 세 단계를 거친다. 첫번째 단계는 특정 테마에 대해 참여자들이 산발적으로 이야기를 나누는 단계이다(‘단계 1’). 다양한 이들의 시선과 이야기들이 모이고 흩어지는 모습 속에서, 일상에서 우리의 시선이 어디에, 어떻게, 왜 닿는지를 엿볼 수 있다. 대화의 대략적인 가이드라인을 위해 몇 가지 질문이 던져질 예정이다.
다음은 ‘단계 1’에서 나눈 대화를 스크립트로 작성하고 그를 바탕으로 토픽(주제어)을 추출한다(‘단계 2’). 선정된 토픽을 중심에 놓고 그와 관련된 단어들을 그룹으로 묶어 토픽 모델을 만든다.

생텍쥐베리의 『어린왕자』를 토픽 모델링 한다면……
예를 들어 『어린왕자』를 토픽 모델링 해보자. 위의 그림과 같이 토픽과 연결된 단어들이 추출된다. 컴퓨터는 『어린왕자』를 분석한 뒤 ‘어린왕자’라는 토픽이 소설에서 유의미한 주제어이며, ‘바오밥나무’ ‘오늘’ ‘장미’ 등의 단어가 토픽과 연관성 있게 사용되었다고 해석한다.
마지막으로는 ‘단계 2’에서 나온 모델을 토대로 ‘시선 지도’를 구현한다(‘단계 3’). 시선 지도는 토픽, 단어와 그를 잇는 선으로 구성된다. 토픽은 그룹으로 묶인 단어들의 중심에 위치하며 각 단어들은 토픽과 선으로 연결된다. 선 위에는 숫자가 적혀 있는데, 이 숫자는 토픽과 단어의 관계를 나타낸다. 선의 길이가 짧을수록, 즉 적힌 숫자가 작을수록, 토픽과 단어는 밀접한 관계를 가지고 있다.
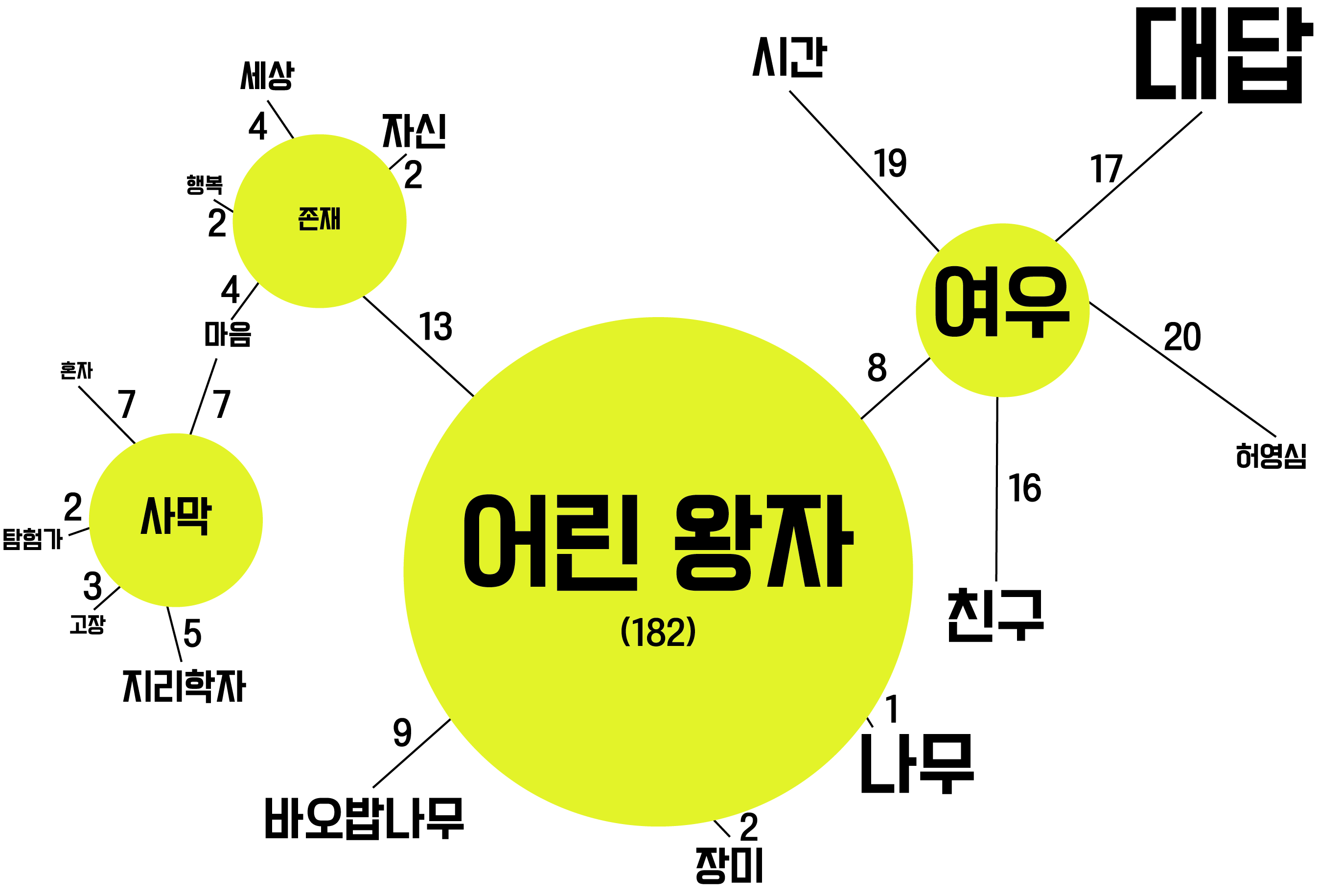
『어린왕자』의 ‘시선 지도’를 그려본다면……
이렇게 만들어진 시선 지도를 모아 앞으로 컴퓨터와 팀원 개개인의 ‘시선 사전’을 만들고, 비교하고자 한다. 하나하나 쌓인 사람들의 ‘삶-문학’은 또다시 ‘시선-사전’이라는 낯선 형태로 표현될 것이다. 완성된 거대한 시선 사전을 펼치면 그 안에서 새로운 시선이 이어지지 않을까 기대하고 있다.
우리의 대화 안에는 일상의 매순간에서 비롯된 마음속 이야기들도 있겠고, 무의식중에 불현듯 떠오르는 생각들도 놓여 있을 것이다. 이는 서로에게 유의미한 정보일 수도, 가볍고 시시껄렁한 헛소리일 수도 있다. 하지만 자신만의 것이라고 생각했던 사적인 고민이나 생각들을 나누며 우리는 자신의 가장 개인적인 부분을 마주하고 가장 자신다운 것을 찾아보려 한다. 일상을 기술이라는 매개체를 통해 바라봄으로써 오히려 지금보다도 더 사적으로 이해할 수 있게 되길 바란다. 거기에서 아주 새로운 것, 우리만의 것이 태어날 수 있을 것이라고 믿는다.
키-ㅌ
‘키-ㅌ’는 문학에 관심이 많은 세 사람이 기술을 도구로 문학을 재해석하기 위해 모인 팀이다. 무언가를 조립해서 만들 수 있도록 부품을 모아놓은 세트인 ‘kit’에서 착안하여, ‘키-ㅌ’는 이야기와 이야기, 사람과 사람을 잇는 다리(-) 역할을 하고자 한다.
2018/02/27
3호